基于eBPF exporter 实现 Kubernetes 和云原生基础设施的可观察性
1. Linux系统性能采集
目前对Linux系统进行性能采集:主要有两个exporter
- node_exporter
- cAdvisor
node_exporter 提供有关基础知识的信息,例如按类型细分的 CPU使用、内存使用、磁盘 IO 统计、文件系统和网络使用情况;
cAdvisor提供类似的指标,但深入到容器级别。可以看到哪些容器(和 systemd 单元也是 的容器cAdvisor)使用了多少全局资源,而不是查看总 CPU 使用率。
但这两类监控都是: 应用层 的统计结果,但是如何直观的监控,呈现 Linux内核中的io操作, 就需要用到eBPF解决方案
2. 什么是eBPF?
eBPF是相对 BPF(Berkeley Packet Filter), eBPF (extended BPF) 在为内核追踪Kernel Tracing、应用性能调优/监控、流控Traffic Control等
本身eBPF已经包含在 Linux 内核中包含了。需要在内核中运行的低开销沙盒用户定义字节码, 需要符合eBPF规范.
规范要求:
- 低开销: 否则我们不能在生产中运行它;
- 通用的: 不会仅仅局限于 io tracing;
- 开箱即用: 第三方内核模块和补丁不太实用;
- 安全: 不能以崩溃为代价,来获得一些指标;
- CO-RE: 一次编译,在不同内核版本上都可以使用;
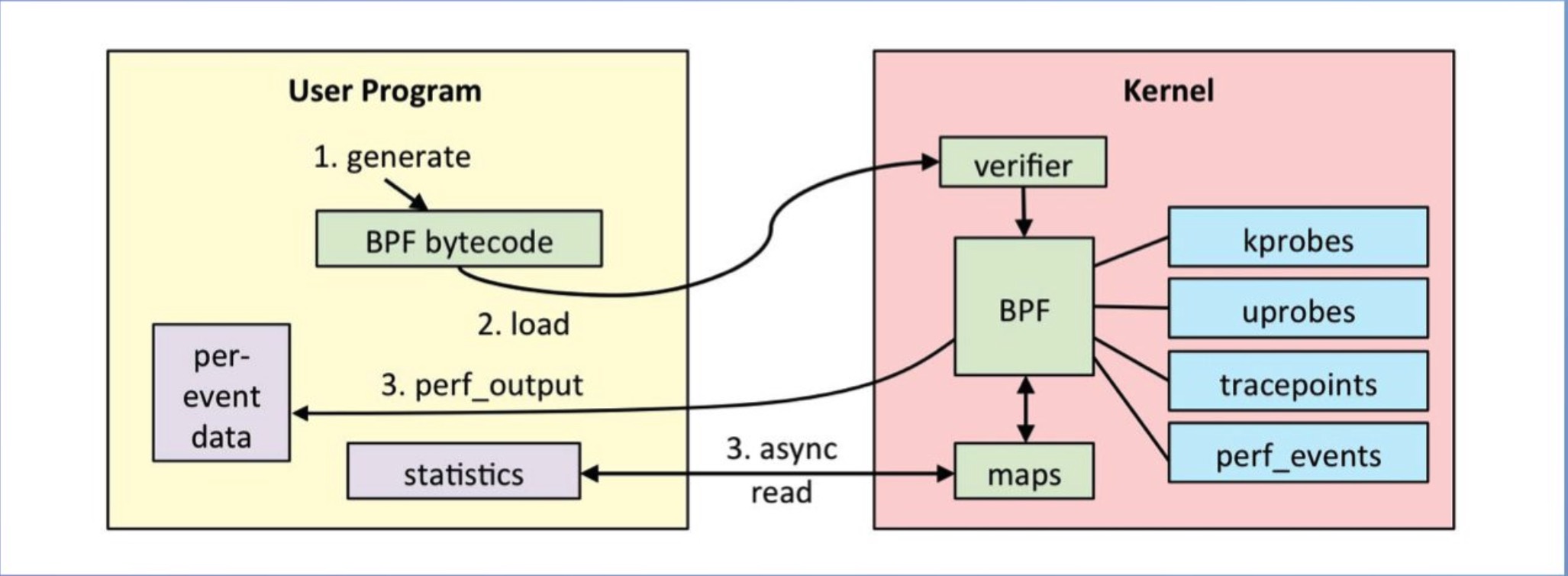
通过c语言编写eBPF程序,然后通过clang/llvm编译器,将BPF程序编译为BPF字节码。然后通过bpf系统调用,将BPF字节码注入到内核中,在注入的时候,我们必须要进过BPF程序的验证,来保证我们写的BPF程序没有问题,以防干掉我们的系统。然后,在判断是否开启了JIT,然后开启了,还需要将BPF字节码编译为本机机器码,以加快运行速度。
当我们BPF程序attach的事件触发了,就会执行我们的BPF程序,然如是经过JIT编译过后的就能够直接执行,然后没有开启JIT就需要通过虚拟机进行解析在执行。在执行BPF程序的过程中,会将需要保存的数据存储到map空间中,用户时候可以从map空间读取出数据。
BPF是基于事件触发的。
比如: eBPF程序attach到kprobe类型的事件上,这个kprobe事件是个函数,当cpu执行到这个函数的时候,就会触发。然后就会执行我们的BPF程序。
3. ebpf_exporter 代码分析
使用 YAML 文件进行配置,可自定义eBPF要提取的系统数据,配置文件主要包括三个部分:
- prometheus可识别的特定格式的数据;
- 附加到BPF程序的探针;
- 要执行的BPF程序。
3.1 配置文件
timer.yaml 定义指标名称和labels信息
metrics:
counters:
- name: timer_starts_total
help: Timers fired in the kernel
labels:
- name: function
size: 8
decoders:
- name: ksym
timer.bpf.c
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include "maps.bpf.h"
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 1024);
__type(key, u64);
__type(value, u64);
} timer_starts_total SEC(".maps");
SEC("tracepoint/timer/timer_start") // 使用tracepoint跟踪timer_start,其中,跟踪点是timer:timer_start
int do_count(struct trace_event_raw_timer_start* ctx)
{
u64 function = (u64) ctx->function;
increment_map(&timer_starts_total, &function, 1);
return 0;
}
char LICENSE[] SEC("license") = "GPL"; // 内核要求必须是GPL license
3.2 配置代码分析
metrics:
counters:
- name: timer_starts_total
help: Timers fired in the kernel
labels:
- name: function
size: 8
decoders:
- name: ksym
timer.yaml中定义了一个名为timers的程序。定义了一个名为timer_start_total的指标,用于对系统中计时器的使用次数进行计数。定义了一个名为function的标签,用来向prometheus提供调用了计时器的函数名,指定了转换函数为ksym。
SEC("tracepoint/timer/timer_start") // 使用tracepoint跟踪timer_start,其中,跟踪点是timer:timer_start
SEC("tracepoint/timer/timer_start") 定义了使用tracepoint跟踪timer_start,其中,跟踪点是timer:timer_start,这个在内核/sys/kernel/debug/tracing/events/timer中可以找到
第三部分 需要执行BPF程序片段
int do_count(struct trace_event_raw_timer_start* ctx)
{
u64 function = (u64) ctx->function;
increment_map(&timer_starts_total, &function, 1);
return 0;
}
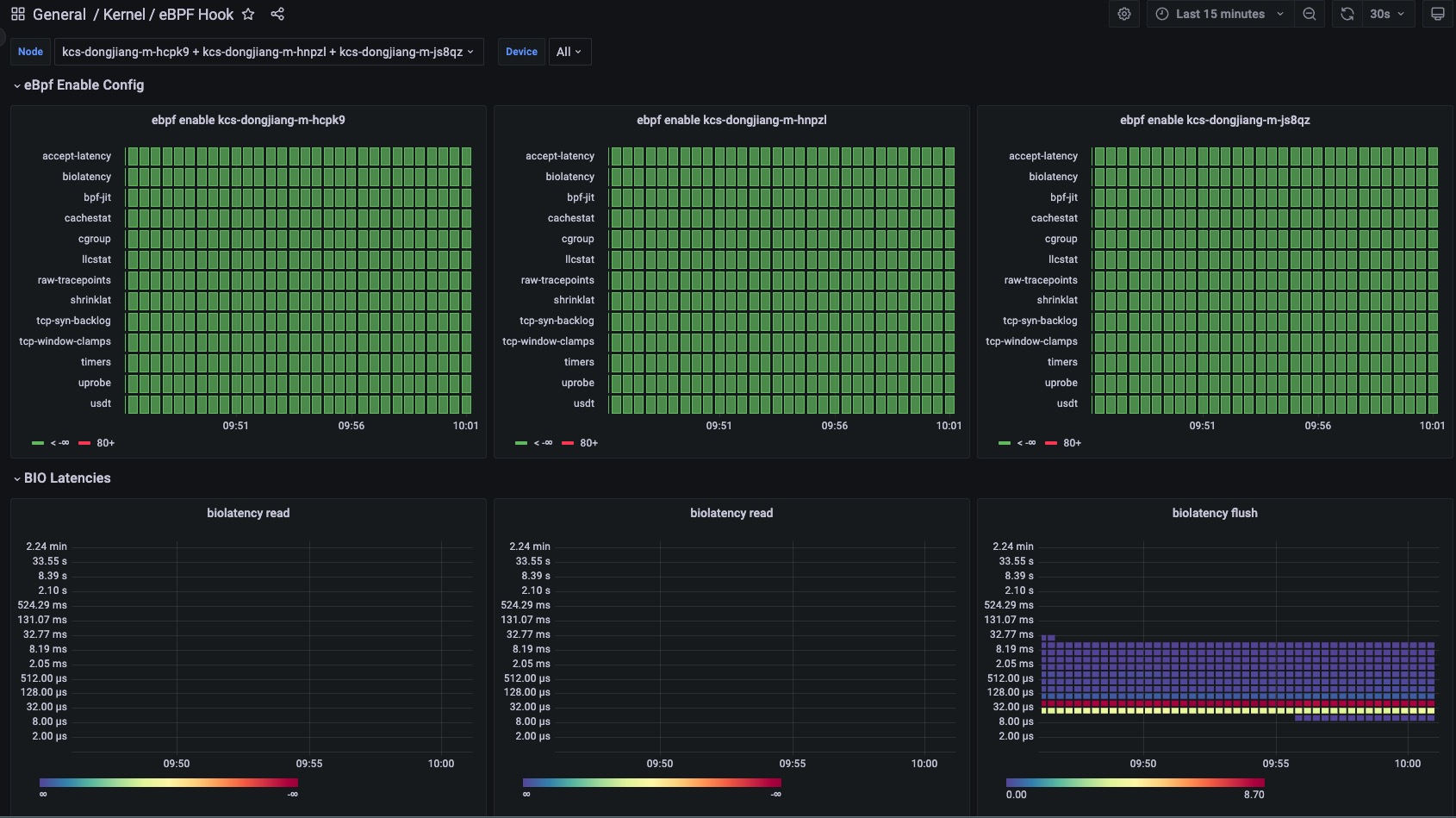
4. eBPF exporter支持hook点
| Hook Point | 功能 | 描述 |
|---|---|---|
| timers | 统计系统中启动计时器的次数 | |
| uprobe | bbp k/uprobe 计数统计 | |
| shrinklat | 磁盘刷新脏页统计直方图 | |
| usdt | USDT 探针 | |
| oomkill | 跟踪 OOMKill内核统计次数 | kernel 5.x 版本以上支持 |
| biolatency | 将块设备 I/O 延迟统计直方图 | |
| accept-latency | Trace TCP accepts延时直方图 | |
| bpf-jit | bpf prog JIT 次数 | |
| cachestat | 计数缓存内核函数调用统计 | |
| cgroup | BPF 程序的检查和简单操作 | |
| llcstat | 按 PID 汇总缓存引用和缓存未命中 | |
| raw-tracepoints | 原始tracepoints统计 | |
| tcp-syn-backlog | TCP SYN backlog | |
| tcp-window-clamps | 测量 tcp 拥塞控制状态持续时间 |
5. 适配低版本内核
对于 Kerenl高版本 5.x 到目前的 6.x, 都满足功能.
对于 Kerenl3.10+ 需要安装部署tot(TCP Option Tracing)插件暴露接
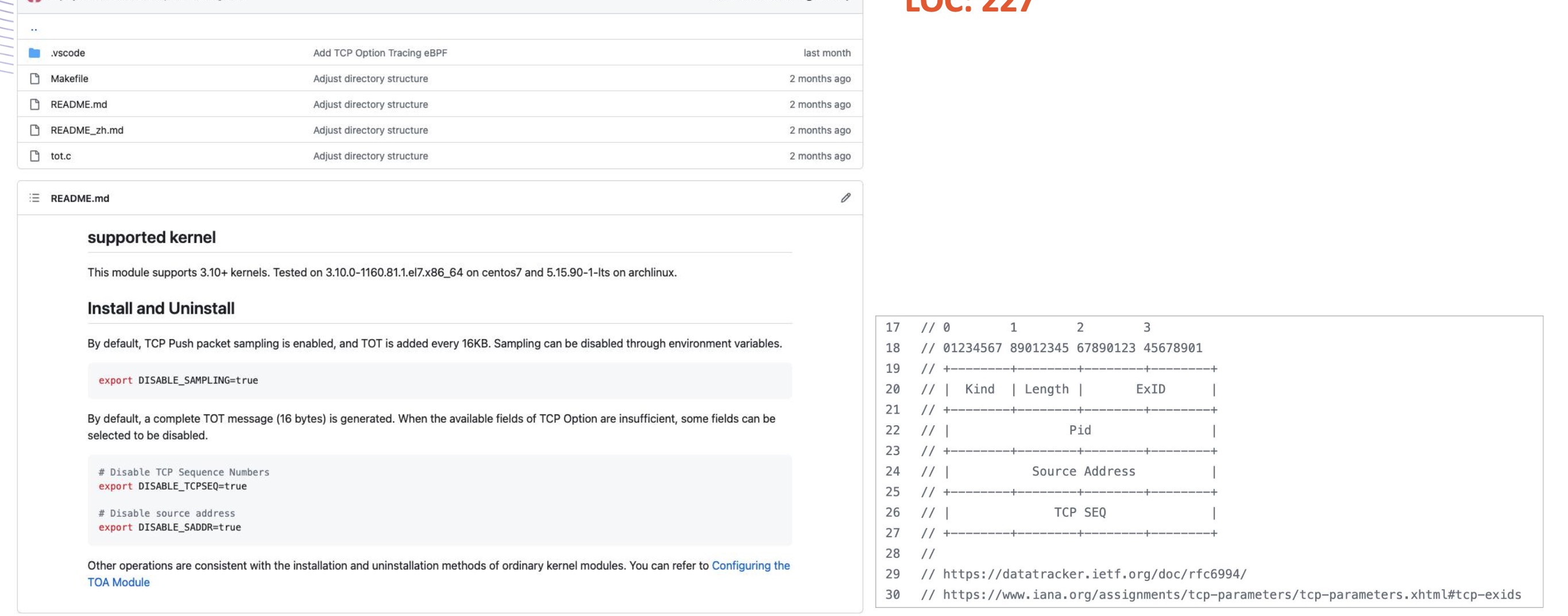
6. 依赖要求
- BCC 迁移到 libbpf 1.1.0: https://github.com/iovisor/bcc/tree/master/libbpf-tools
- Kernel 要求 4.15+
7. 部署
7.1 ebpf exporter 安装
helm 方式部署: 支持arm64和amd64环境 https://artifacthub.io/packages/helm/kubservice-charts/kubeservice-ebpf-exporter
7.2 grafana 监控
grafana dashboard:https://grafana.com/grafana/dashboards/18612-kernel-ebpf-hook/